Be bold and try something new!
We are sometimes afraid to experiment.
Especially within the work environment, where it’s often considered as a loss of time (hence money) compared to doing things that we already master.
Because of that, finding talents often turns into matching hard skills as a safe way to achieve goals rather than soft ones including personality, autonomy and overall growth potential.
In this context, I decided to run the following experiment:
Try something new. Something I don’t know anything about.
See how it goes, and capture how much effort it took to reach the different stages.
Challenge
Here is the challenge:
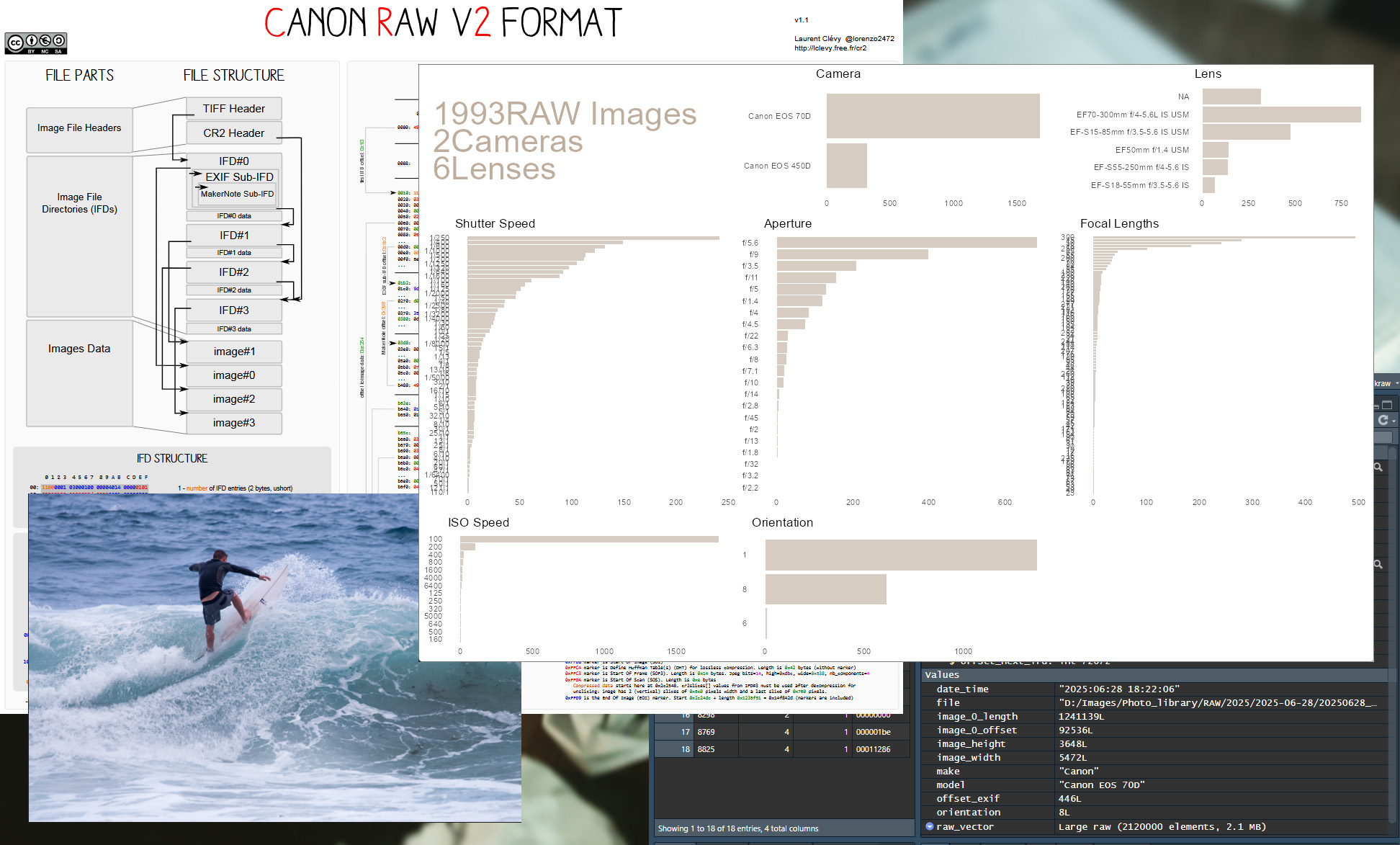
Read Canon raw files (photography as captured by the camera sensor) & extract the metadata to build some plots out of the photo library.
The RAW format
A word about the RAW format.
Raw files are photography as captured by the camera sensor. They carry all information needed to render / develop the photography as an image (for example in Abode Lightroom). Canon has a specific raw file format (CR2) that fits with their own schema. The schema tells how to read, navigate & translate the file to extract human readable information.
Baseline
I know the RAW format because I’m doing some photography, but I never opened those files out of Abode products (basically file + open).
Everything I knew about it is “it contains camera sensor information for me to tune brightness, contrast, saturation and so on”.
I didn’t know anything about binary files except everything in computer science ends up in 0 or 1 either in memory or on disk.
Outcome
Here are the outcomes of this experiment:
1h effort - explore
Understand there is no easy path to do it (that’s usually where we would decide to stop)
No R package or functions I could find online (C & Pythons libraries exist)
It will require reading binary files (basically a huge sequence of 0 & 1) & turn them into hexadecimal sequences to decode
Canon raw (CR2) files have a complex specification (Japanese style)
Find a great base schema how to read the file from the hexadecimal sequence of values
Understand the file actually contains several images & ‘image file directories’ (IFD)
1.5day effort - prototype
Read the binary file as a sequence of hexadecimal values (I tried a package but finally decided to go with R base functions)
Understand the basics about ‘endianess’ (order in which the bits are written on disk)
Understand how to navigate & retrieve values from sequence of bytes (offset)
Write basic functions to capitalize above notions
Match the first sequences of bytes with the CR2 schema and recover the expected info:
(endianess, Canon raw marker, image width & height)
2 days effort - develop & package
Get the EXIF/Canon hexadecimal reference tags & write mapping
(ex: tag 0x0100 for ImageWidth)Define list of tags to keep
Rework prototype functions (clean, order, factorize & vectorize, structure sequence of calls)
Extend from prototype to extract all selected metadata
Extend from prototype to extract the images (the raw file contains 4 images)
Extend from prototype to wrap extracted metadata into a list
Extend from single file read to folder scan & return a data.frame of metadata
Implement basic data visualization function
Build package from all above
Next steps could be to:
extract information from the image itself (colors) to allow color based search for example
check for image classification based on the thumbnails
Conclusion
It took me about 4 days (including capitalizing the experience in this post) to go from “I have no idea how to achieve this” to say version 0.9 of a package.
There are for sure improvements that need to be done to get a version 1.0
In particular, I discovered that lens information are not available for one of the camera I owned. Most probably it’s contained in a different tag (many are redundant in the file)
This represents 316 out of 1993 files 15.85% on a single metadata.
Even with this limitation in mind, investing 4 days of work into this experiment was a great experience and achieved result is actually above my expectations.
This was an opportunity to capitalize knowledge about:
binary files, endianess, hexadecimal sequences & corresponding schema
extracting human readable information from hexadecimal sequences
file architecture in general and RAW format in particular
As an example, with a deeper knowledge of binary files, I now understand why .parquet format is much faster reading / writing data.frames than .csv (as far as parquet file are written column-wise, it means there is no need to navigate the binary file from an offset to another to retrieve the sequences of a column because it in fact a single sequence of bits!)
Of course, knowing about the Canon Raw format is not a knowledge I’m going to reuse very often.
But the skills about binary files, how to decode them and file architecture in general is key to master I/O performances.
Takeaway
The key takeaway for me in this experiment is that even with say 80% of missing skills toward the goal, It only took me 4 days to define a path toward the objective, learn those missing skills and capitalize on them to end up building a package.
And that is possible because – I believe – the purpose of an engineer (or any technician) is not to know everything, but to know how to learn everything.
To extend to the global work environment, I believe it’s a mistake to hire people mainly based on matching toward a list of hard skills.
We tend to consider that mastering an exhaustive list of hard skills increases the probability of success until it becomes a certainty.
That is a wrong assumption. Mainly because cloning projects is described as one of the main reason for failure (or at least failure to achieve the expected ROI).
Instead, we should evaluate the potential for a given profile to reach the goal – that is to say the ability for someone to learn and capitalize missing knowledge.