Smart Cache & Communication Architecture
My GitHub client app just got a new smart cache & communication architecture!
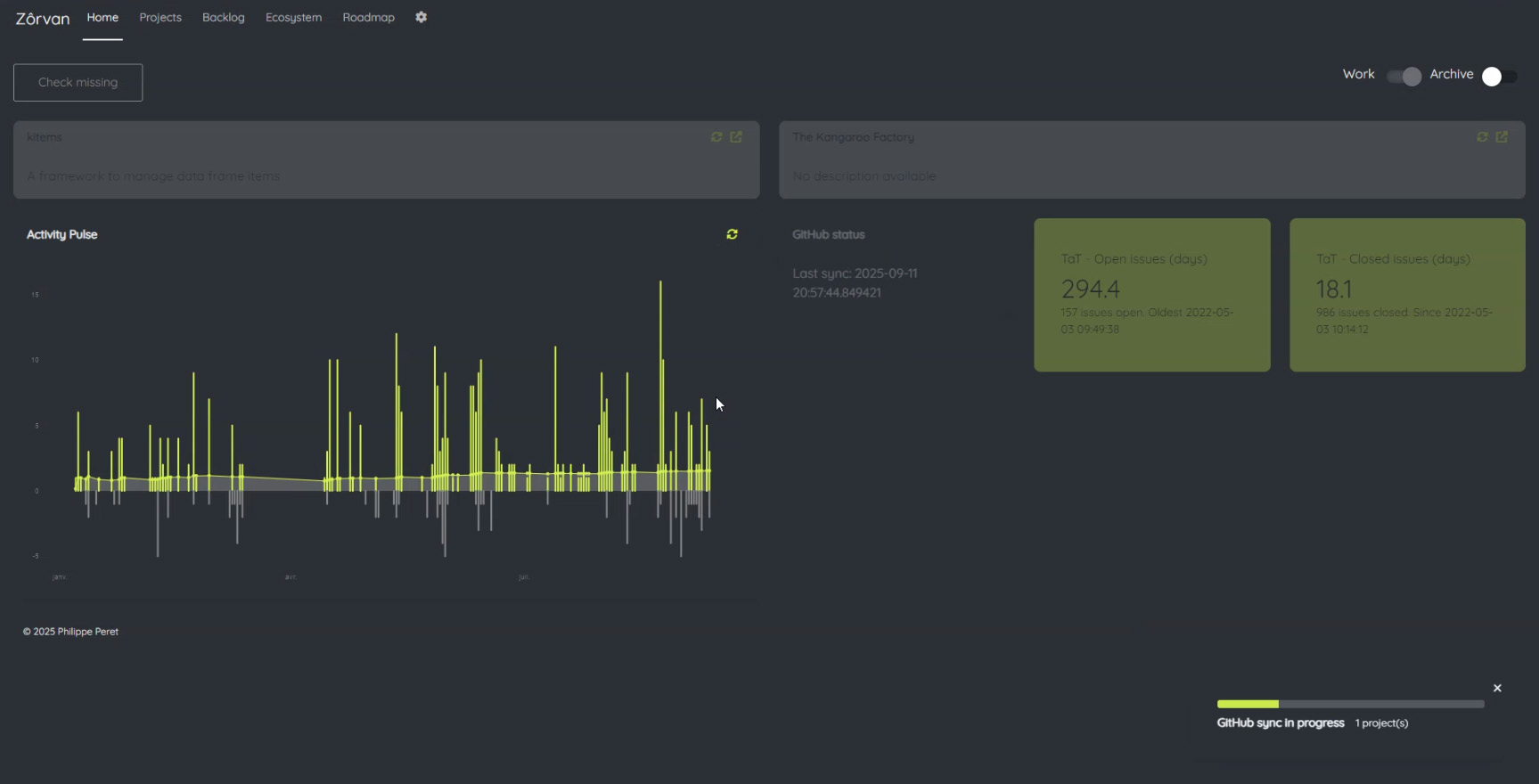
Smart Cache
In the first prototype, the app was already based on a cache mechanism.
The main reason for that is because the GitHub API call is quite costly. The API responses are VERY verbose (incl. redundant nested data), so that there is a latency that can’t be ignored even for a few hundreds of repositories / milestones / issues.
But that cache mechanism was basically based on saving the API responses in a .rds file that could be loaded instead of calling the API, checked against its timestamp and either return its content or call the API if the information was considered as outdated.
One thing you should – if not already – know about cache is that with great power comes… great responsibilities. As you solve performance issues by caching the information, you create another problem that is cache synchronization.
There is always a risk of disynchronization between the cache and the ‘source of truth’ that needs to be treated with great care (I have been dealing with cache sync issues since day 1 of doing customer support at Dassault Systèmes).
For this reason, I decided to split the app internal data source from the cache synchronization mechanism. Basically, instead of checking the cache status to display a milestone (and decide to call the API or not), the app now just displays the current milestone (the cache version).
Then, in the background, the cache is synchronized with GitHub based on smarter criterions:
the project state
specific per state timeouts that can be tuned in the settings
using ‘since’ parameter of the API to only get the updated resources
through scheduled jobs that start automatically
or manually if the user wants additional sync on a specific project Only the updated resources are replaced in the internal data source.
Another reason for this internal data source is that I want to manage non-GitHub project as well.
Communication Architecture
The second part of this new version of the prototype was to review the app architecture based on the module communication manifest I wrote in the ‘Mastering Communication between Shiny Modules’ book. Basically the architecture I am promoting is to split the data vs feature modules and keep a strict encapsulation throughout the app.
This prototype is a great opportunity to demonstrate how efficient this architecture is.
A data manager module has been created with its own server to… serve the data across the app.
All the internal data sources are managed through the {kitems} framework I am developing since 2020, with dedicated child servers.
The data manager module also manages all the cache sync tasks (passing create / update / delete tasks to the kitems servers).
The feature modules mimic the UI (here it’s based on a tab layout) to keep UI-server communication encapsulated at the same levels. They communicate with the data manager module ONLY through function reactive parameters & return values.
This new version is also an opportunity to demonstrate the latest improvements delivered in {kitems} to support mixed implementation.
I will work on a specific post but basically creating the ~1k issues I have in GitHub inside the internal data source for this app takes.. almost no time (especially compared to the API response time).